Search Bench
Search Bench is a community-driven experiment that compares search engines without showing which engine produced which results. Inspired by LLM Arena, it presents two anonymous result sets side-by-side, asks you to pick which you prefer (or mark them as similar), and aggregates those blind votes into a public leaderboard.
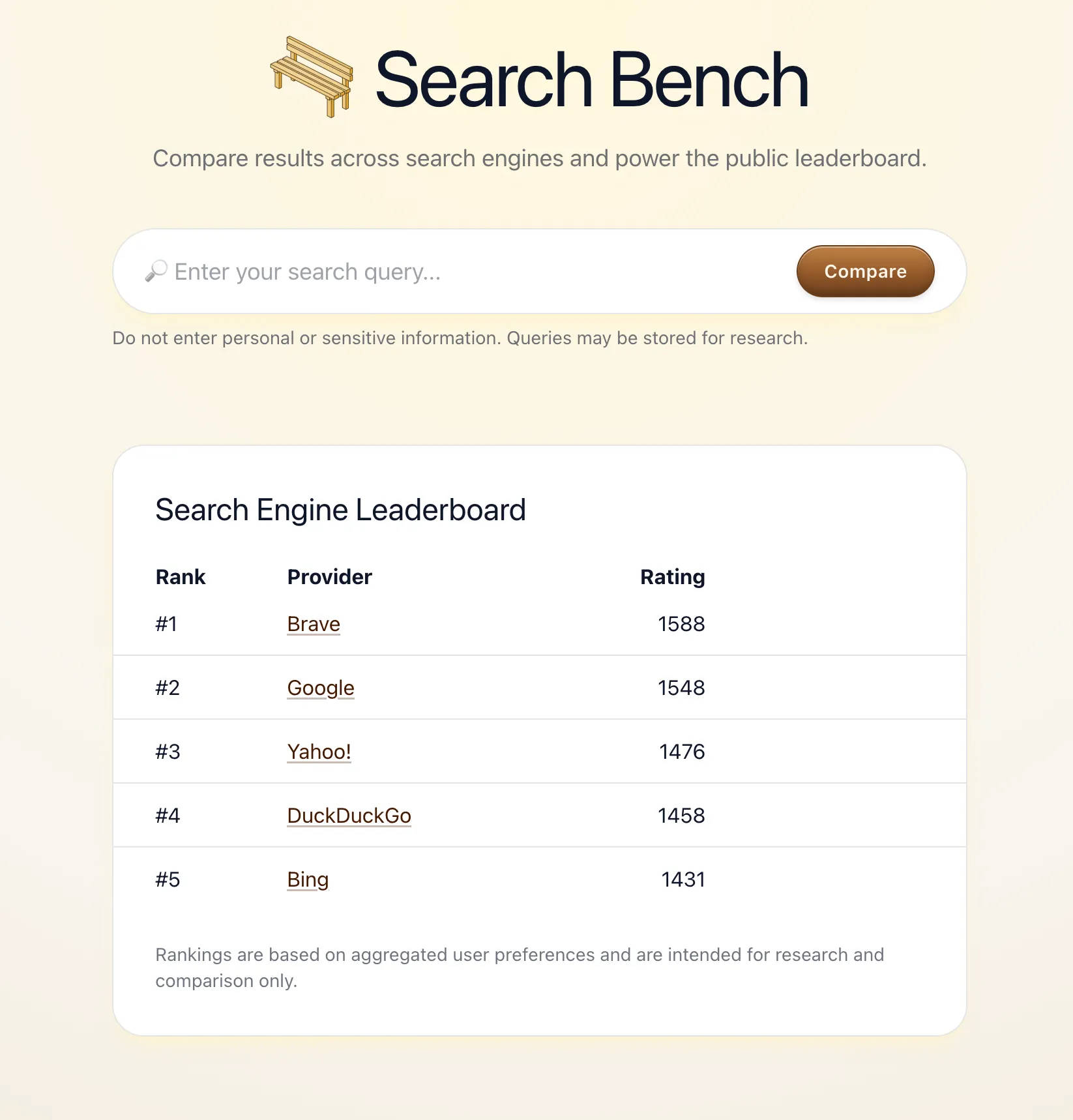
Methodology
Each vote is a pairwise comparison: you see results from two engines and choose one, or call it a tie (counted as 0.5 win each).
Scoring uses a Bradley–Terry model:
- Ability scores are updated iteratively and normalized by geometric mean.
- Final scores are log-scaled:
1500 + 400 × log₁₀(ability), producing an Elo-like scale.
Matchup selection is adaptive — it prioritizes under-sampled search engines and close matchups via an uncertainty × closeness weighting, so the most informative comparisons are shown more often.
Caveats
Search Bench is intentionally not an objective ranking: queries and voters are self-selected, results vary by context, and “prefer” is subjective. The goal is to explore whether removing brand bias reveals a real preference signal at scale, and how that signal shifts as more independent voters contribute.
See also the launch blog post.
Technologies used:
- Next.js,
- Tailwind CSS,
- SQLite.